Get more insights from Confluence pages with CSV data export
Confluence has a habit of growing quietly. What starts as a well-organized workspace — a few spaces, some project documentation, team notes — gradually expands into a large knowledge base. Pages accumulate, teams change, projects end, and before long, Confluence contains hundreds or thousands of pages that feel important but are surprisingly hard to evaluate.
As a result, most teams run into familiar questions:
- Which pages are outdated?
- Which content is still relevant?
- Who owns what?
- What information is nobody actually using?
Hereby, the challenge isn’t a lack of data. Confluence already contains the signals you need. However, the difficulty is seeing patterns across large volumes of content rather than page by page. This is exactly where CSV data exports become valuable.
Why Confluence analytics often falls short
Confluence provides built-in features for understanding and managing content, and for many day-to-day tasks they work well.
For example, Confluence Cloud includes page insights, where users can view metrics such as total views, viewer trends, and read statistics directly from the page analytics sidebar.
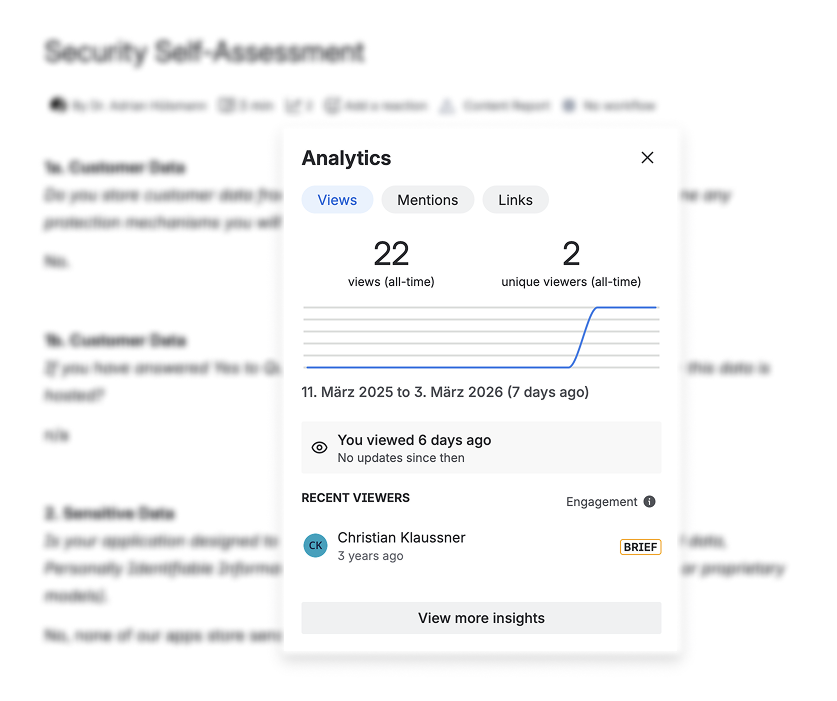
Confluence also offers administrative tools like the Content manager, which helps space owners navigate, filter, and bulk manage pages within a space. Filters such as last updated date or page owner are particularly useful for cleanup tasks.
These native capabilities are valuable, especially for page-level inspection or individual space maintenance.
However, they are primarily designed for interactive exploration, not large-scale analytical workflows. Once you try to diagnose patterns across many spaces or generate datasets for deeper analysis, certain limitations become clear:
- Analytic scope is limited — page analytics are typically tied to individual pages or spaces
- Cross-space analysis is cumbersome — comparing metrics across spaces often requires manual inspection
- Bulk reporting workflows are constrained — Confluence does not natively provide analytics-ready exports across your instance
To identify systemic issues — such as stale documentation across all spaces, ownership gaps, or engagement trends — teams usually need structured datasets that can be sorted and filtered externally.
This is exactly where CSV export becomes useful.
What CSV Export Actually Unlocks
Exporting page metadata into CSV fundamentally changes how you can work with Confluence content.
Instead of browsing and estimating, you can:
- Sort pages by update history
- Filter content by ownership
- Detect stale documentation
- Identify low-engagement pages
- Compare patterns across spaces
In practice, this turns your Confluence environment into something analyzable rather than merely navigable. And instead of relying on what you happen to come across while browsing, patterns that are almost invisible inside the UI become immediately obvious in a spreadsheet.
Exporting Confluence Data with Breeze
While Confluence stores rich metadata, getting that data out in a structured, usable format isn’t always simple. Breeze removes that friction by providing built-in space-level and page-level CSV exports, making it easy to analyze your content at scale.
At the same time, CSV export is just one part of what Breeze is designed for. It acts as a document management and governance layer for Confluence, helping teams bring structure to how content is reviewed, validated, and maintained over time.
This becomes especially valuable in larger Confluence environments, where content lifecycles, ownership, and quality control are difficult to manage manually. Instead of relying on ad-hoc updates, teams can define review and approval workflows that make documentation more predictable and transparent.
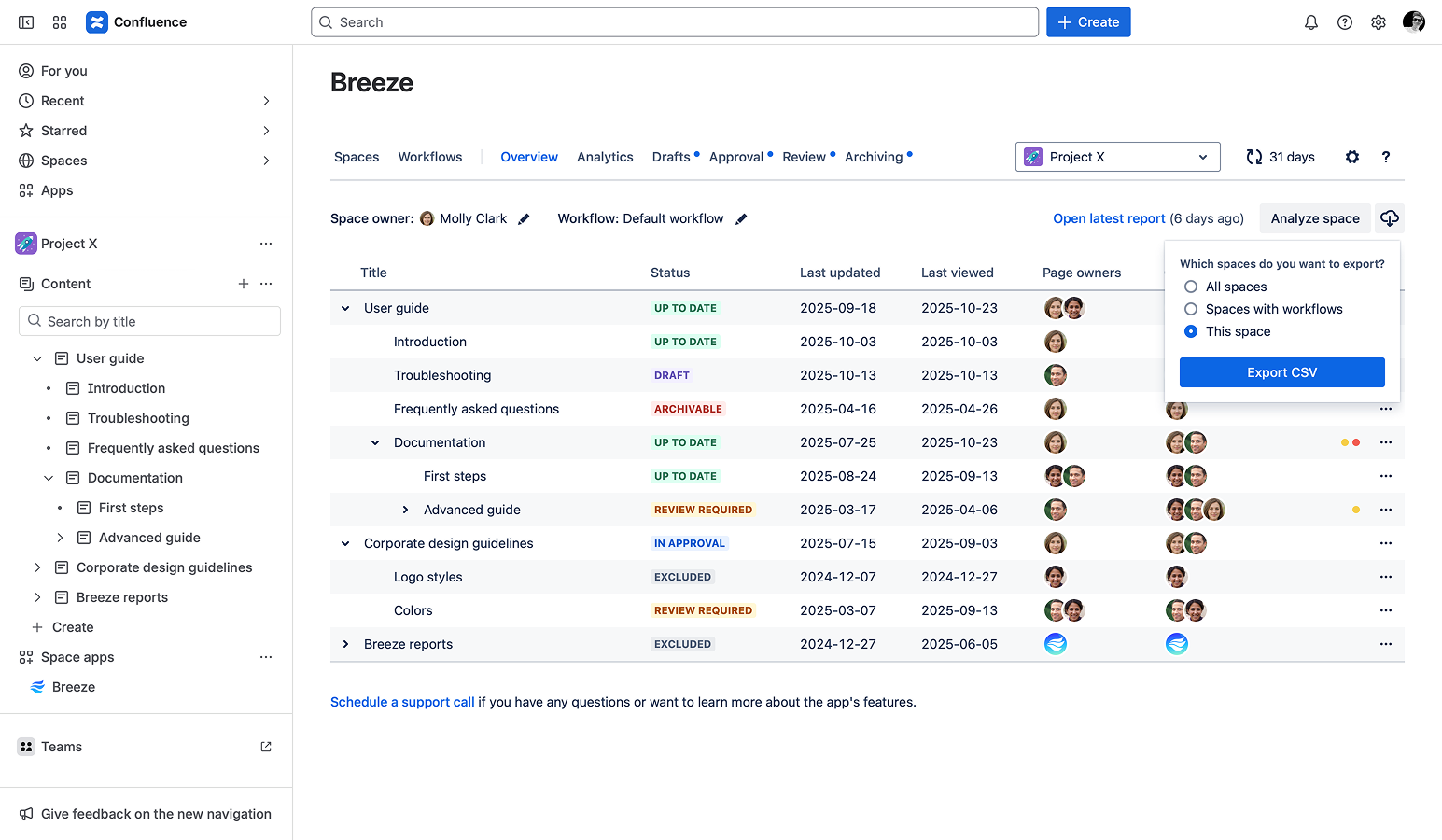
The export functionality builds on top of that foundation — giving you direct access to structured data so you can analyze, report on, and continuously improve your content across spaces.
To support different levels of analysis, Breeze provides two types of CSV exports depending on whether you want a high-level overview or detailed page data.
Space-Level Export
The space-level export provides a high-level snapshot of each space’s status and content health. This is particularly useful when comparing spaces or generating management-level reports.
The resulting CSV includes fields such as:
- Space key
- Space name
- Space owner
- Categories
- Last analysis date
- Total number of pages
- Number of pages per status
- Health score
- Assigned workflow
With this data, you can quickly answer questions like:
- Which spaces have the highest proportion of outdated pages?
- Which spaces are actively maintained versus largely neglected?
- How does content health compare across teams or departments?
In practice, teams often use this export to:
- Build dashboards that track space health over time
- Identify spaces that need cleanup or review initiatives
- Prioritize governance efforts based on size and content quality
- Report on documentation status to stakeholders
This makes the space-level export particularly valuable for high-level oversight and governance, where understanding overall trends matters more than individual pages.
Page-Level Export
For deeper analysis, the page-level export provides detailed metadata for individual pages, making it possible to evaluate content at scale rather than page by page.
The resulting CSV includes fields such as:
- Space key
- Space name
- Space owner
- Page ID
- Page title
- Status
- Created at
- Last viewed
- Last updated
- Page creator
- Last contributor
- All contributors
- Page owners
- URL
- Labels
With this level of detail, you can move beyond high-level trends and start working directly with your content.
For example, you can:
- Identify outdated pages by filtering
Last updated - Detect ownership gaps by filtering
Page ownersfor unlicensed users. - Find low-engagement content based on
Last viewed - Analyze how content moves through lifecycle stages using the
Statusfield
This makes it easy to run targeted audits, such as:
- Building lists of pages that need review or archiving
- Reassigning ownership after team or role changes
- Detecting heavily used pages that may require updates
Once exported, the data can be explored in tools like Google Sheets, Excel, or BI platforms to create dashboards and driver further analyses.
Compared to manual page-by-page inspection, this approach provides a much clearer and faster way to understand how your documentation actually evolves.
From Visibility to Better Confluence Governance
As Confluence instances grow, maintaining content quality becomes less about adding structure and more about gaining visibility. What starts as a well-organized workspace can quickly turn into a large, hard-to-evaluate system — unless you can step back and see how content is actually evolving.
That’s where structured data makes the difference.
CSV exports allow you to move beyond assumptions and work with clear signals — whether you’re identifying outdated pages, resolving ownership gaps, or improving content lifecycle processes.
Breeze makes this step straightforward by turning your Confluence data into something you can analyze, report on, and act upon.
If your documentation environment is expanding, this shift — from navigating pages to analyzing content — is one of the simplest ways to regain control.
Make your Confluence data actionable
Breeze lets you export and analyze your Confluence content at scale to identify outdated pages, ownership gaps, and content that needs attention.
Try for free Schedule a demo